

The spending of public funds for research requires the auditing process for accountability, in which, the line items of expenditures are matched to the broad categories requested at the proposal stage. Given the long lists, the auditing process is highly tedious. With automation as a solution, the “A* Grant Audit Flagging System” (A*GAFS) was created for automated matching of approved items. Utilizing Optical Character Recognition (OCR), Natural Language Processing (NLP), and allowing customizations to thresholds on stringencies, A*GAFS flags out the possible non-fundable purchases by highlight and comments. This application allows the automated comparison of expenditures with the requested item in the grant proposal to minimize manual labor where hired staff, dates, and items would all be screened. A*GAFS is a standalone application compatible on both Windows and MAC OS.
Grant offices have the social responsibility of research fund administration, ensuring that they are used for the stated research. Depending on various localities, stringency can vary accordingly. In the case of audits to enforce correct spending, manual checks of lists with discernment is a tedious task. Given that scientific research items are often jargons, best known exclusively to those in the field, discernment is hard to come by. This contributes to frustration and friction between scientists and administrators within the fluid nature of scientific research where research outcomes cannot be pre-determined. To alleviate these problems, we designed a software for our agency grant office to automate screening called the “A* Grant Audit Flagging System” or A*GAFS.
A*GAFS is a tkinter Python program that highlights potential discrepancies in grant expenditures by comparing the grant proposal forms (PDF) to the financial expenditure list in Microsoft Excel spreadsheets. It aims to serve as a preliminary screening method to flag items and reduce manual screening. This software complements and forms a more holistic software solution package with two other applications - A* Capability & Expertise Search (A*CES) and A* Review Assistance System (A*RAS) - for searching for experts in specific areas, and the reviewing of grants, respectively.
A*GAFS was developed using Anaconda Navigator and Terminal (1.9.7) using Python 3.6. tkinter (Python Software Foundation, 2019) was used to create the GUI for the Python script; Openpyxl library (Gazoni & Clark, 2019) for the manipulation of Excel spreadsheets with Python; and OCR to capture text from the grant proposal forms (PDF to image) using pytesseract (Lee, 2019), PIL (Clark & Lundh, 2019), pdf2image (Belval, 2019), and PyPDF2 (Phaseit, Inc., 2016).
NLP was used to extract name entities from the text and to get a thesaurus of words corresponding to the categories in grant proposals and Excel spreadsheets. The libraries used for NLP are nltk (NLTK, 2019), Stanford CoreNLP (Manning, et al., 2014), and Java (Java™ Platform, 2018).
Through the synergy of these libraries working together, A*GAFS acts as an A.I. based audit screening tool.
Upon launch, an onboarding/splash page with instructions would be shown (Figure 1). This page serves as a tutorial for A*GAFS.
Figure 1: Instructions page
Following which, the window prompts the user to select a folder containing the grant proposal PDF form(s). Multiple PDF forms in the folder can be selected to screen multiple proposals. Backend, the program converts the uploaded PDF into an image (convert_from_path) for the OCR (pytesseract) to extract the text that is then appended to a dataframe for subsequent processes.
The next page prompts the user to select a spreadsheet containing the grant purchases. Several methods were employed to get the spreadsheet data. The Project IDs in the grant PDF forms are matched to the spreadsheet rows with the same Project ID. This process loops through each PDF form and matches the project ID in each form to the relevant rows (Figure 2). The data is also screened to match dates with the grant form. Dates are extracted from the text using regular expressions and a month dictionary.
If travel venues are to be audited, the data from the spreadsheet can also be compared to the PDF form. This method checks that the conference/event is not local since it has the “overseas” votecode. For example, grants for overseas travel not allowing local conferences, will cause local expenses to be flagged up. In verifying the venue, if the votecode is is “overseas”, pycountry (Theune, 2019), a Python library for countries, will be referred to. In our application, the pycountry countries list was extended.
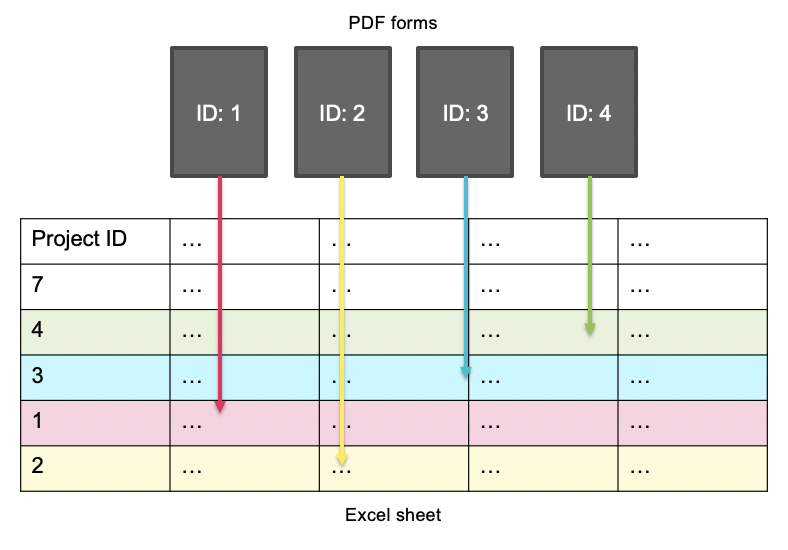
Figure 2: Illustration of grant matching between the PDF forms and Excel spreadsheet
The description in the spreadsheet sheet will be compared to the country list excluding Singapore. Should a location be missing from the description, the program search the Internet for the name of the conference/event stated in the spreadsheet. A “feeling lucky” Google search will be performed to screen the html of the page for 'Singapore’. If 'Singapore' is in the text, the line item would be flagged.
Similarly, personal expenses would be screened against the project staff list in the proposal if they are named. Since names are inherently difficult to sieve out from a chunk of text, the Stanford NLP was used for this task. As the Stanford NLP required Java, a Java executable was added to the A*GAFS program.
The similarity score threshold determines the stringency of the checks between the relevance of the grant item in the spreadsheet to the original PDF grant proposal. If the proposal requests for budget in programming, but has purchased a yacht, A*GAFS will be able to detect and flag the discrepancy. The NLP feature allows checks of the item purchased against the description of the grant to give a similarity score. If the score is within a threshold, the “mismatch” would be tolerated.
Given the numerous jargons used in research and the local grant office nomenclature, the accuracy of the checks was compromised. In one such example, certain “lab equipment” are typically not recorded in the nltk text similarity algorithm so a categorical list for “lab equipment” was created to include common laboratory materials (Figure 3).
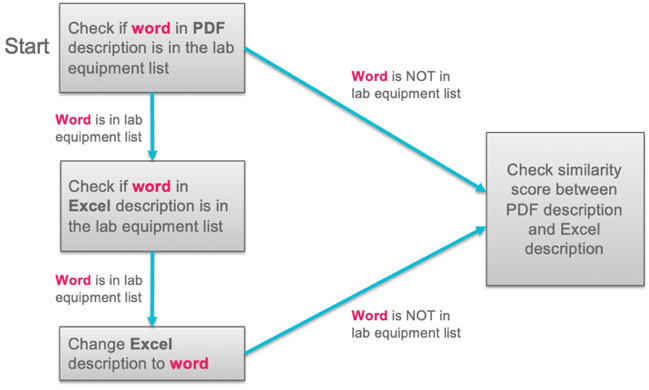
Figure 3: Categorical lists with Spreadsheet and PDF descriptions
For further customization, an example would be the “lab equipment” categorical list (EPA.gov, 2019) which can be modified from the project folder. Simply find the list to modify (e.g. lab_eqpt.py) and add in the word to the list in single quotation marks (Figure 4).

Figure 4: Adding a word to a categorical list
In the user interface, the similarity score threshold can be customized by the slider on the main page (Figure 5). The similarity score ranges from 0.0 to 1.0, with 0.0 being very tolerant to 1.0 being stringent (very similar or exact match).
When the user ticks the box for the parameter to be screened, the Boolean value will be “1” which indicates ‘true’ for the parameter to be checked.
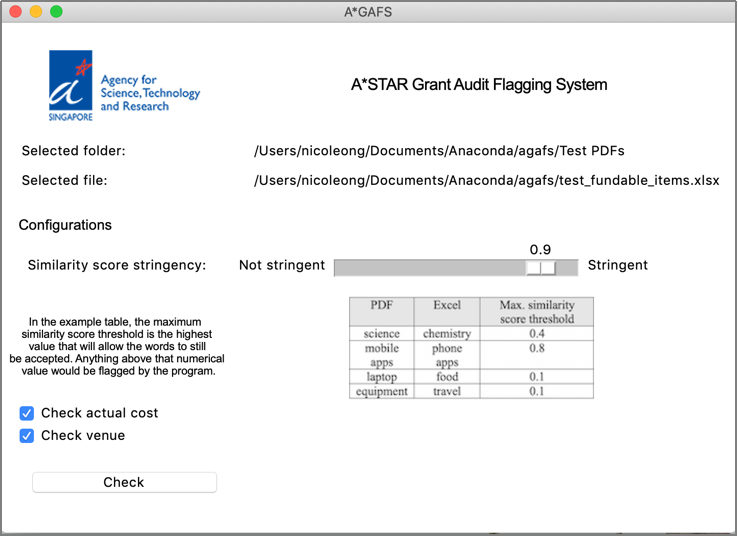
Figure 5: Main page of A*GAFS
Clicking on the “Check” button, initiates the data extraction from the uploaded PDF(s) and spreadsheet. Once the process is completed, a new spreadsheet with the matching results would be created.
The program will show a ‘Done’ label below the ‘Check’ button to which the user can now view the new spreadsheet (Figure 6) that is one level up in the directory from the ‘agafs’ folder.

Figure 6: Final spreadsheet
The green highlight indicates that the item is approved and matches the grant. Yellow highlights items for manual checks, whereas the red highlights mismatch of the item to the grant proposed. A new column at the right provides the rationale to the line item highlighted for yellow or red rows.
The program was tested within Anaconda, where pyinstaller (Cortesi, 2017) was also used to convert the python file into an executable. With the tkinter program converted into an executable file, users can simply click on the desktop icon without having to install the application (e.g. pip install nltk, etc.), thus allowing it to be run as a standalone.
A video demonstration of the software can be found here
Tweaking the similarity score threshold varies the results and colors of the highlights in the final spreadsheet. A small demonstration to examine the similarity score thresholds for multiple words is shown in Figure 7. The maximum similarity score threshold is the highest value that will allow the words to retain relevance and be tolerated. Anything above that numerical value would be flagged by the program.
| Excel | Max. similarity score threshold | |
|---|---|---|
| science | chemistry | 0.4 |
| mobile apps | phone apps | 0.8 |
| laptop | food | 0.1 |
| equipment | travel | 0.1 |
Figure 7: Table of similarity score example word tests and results
These results aim to provide a clearer example of how the similarity score threshold works and to allow the user to gauge what threshold is appropriate for the item to be checked (Figure 5).
A*GAFS provides the benefits of automation to screen for discrepancies in grant audits. Solutions such as A*GAFS present opportunities to eradicate tedious business process like pre-auditing of grant expenditure in the near future using AI.
A*GAFS belongs to the Agency for Science, Technology, and Research (A*STAR) of Singapore, and is for internal use. Interested parties may write to the corresponding author who may make the request to the relevant departments.
We thank the Science and Engineering Research Council (SERC) grant office Ms Ei-Leen Tan for the funding of this work, as well as provision of the data for tests. The work described here forms part of the industrial attachment for NBO in fulfilment of the requirements of the Diploma in Information Technology by Temasek Polytechnic, Singapore.
To avoid conflict of interest, the article was handled by an independent member of the editorial board. The article-processing-charge for this article was also waived for A*STAR. The software is for internal use and is not commercially sold.
NBO developed the tkinter Python program and drafted the manuscript. WLW and KFC supervised the development and testing of the program. SKEG provided the resources and supervised all aspects of the project.
NLTK. (2019). Natural Language Toolkit. Retrieved from NLTK: http://www.nltk.org/
Manning, C., Surdeanu, M., Bauer, J., Finkel, J., Bethard, S., & McClosky , D. (2014). The Stanford CoreNLP Natural Language Processing Toolkit. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, 55-60.
Lee, M. (2019). pytesseract. Retrieved from PyPi: https://pypi.org/project/pytesseract/
Clark, A., & Lundh, F. (2019). Pillow. Retrieved from Pillow: https://pillow.readthedocs.io/en/stable/
Belval, E. (2019). pdf2image. Retrieved from PyPi: https://pypi.org/project/pdf2image/
Gazoni, E., & Clark, C. (2019). openpyxl - A Python library to read/write Excel 2010 xlsx/xlsm files. Retrieved from openpyxl: https://openpyxl.readthedocs.io/en/stable/
Java™ Platform. (2018). Java™ Platform, Standard Edition 7 API Specification. Retrieved from Oracle: https://docs.oracle.com/javase/7/docs/api/overview-summary.html
Phaseit, Inc. (2016). PyPDF2. Retrieved from PyPi: https://pypi.org/project/PyPDF2/
Python Software Foundation. (2019). Graphical User Interfaces with Tk. Retrieved from Python: https://docs.python.org/3/library/tk.html
Cortesi, D. (2017). PyInstaller Manual — PyInstaller 3.2.1 documentation. Retrieved from Pyinstaller.readthedocs.io: https://pyinstaller.readthedocs.io/en/stable/
Theune, C. (2019). pycountry. Retrieved from PyPi: https://pypi.org/project/pycountry/
EPA.gov. (2019, Sep 4). Safer Chemical Ingredients List. Retrieved from EPA.gov: https://www.epa.gov/saferchoice/safer-ingredients

